{kind=link}

Auditable · Governed · Explainable · Production-Ready


Website · Docs · Discord · Twitter/X · YouTube · PyPI · Changelog
Most AI agents act without a trail.
They store embeddings, not meaning. They make decisions that cannot be audited, recall context that cannot be explained, and produce outputs that cannot be traced back to a source. Regulators, auditors, and enterprise risk teams ask the same question: can you prove what your AI did and why?
Semantica is the Context and Accountability Layer that sits alongside your LLM, vector store, and agent framework. It complements your existing stack, not replaces it, adding structured intelligence, causal reasoning, and a full audit trail to every decision your agents make.
Core capabilities:
- Context Graphs: A structured, queryable graph of everything your agent knows, decides, and reasons about
- Decision Intelligence: Every decision is a first-class object: traceable, searchable by precedent, and causally linked
- AI Governance: Policy enforcement, SHACL constraints, conflict detection, and compliance rule checks built in
- Full Auditability: W3C PROV-O provenance on every fact, with audit trails exportable to JSON, CSV, or RDF
- Reasoning Engines: Forward chaining, Rete network, Datalog, and SPARQL with fully explainable paths, not black boxes
- Drop-in Integrations: Agno native, 12-tool MCP server, 50+ CLI commands, 109 REST endpoints, plugins for 8 editors
Quick Start · Architecture · Why Semantica · Context Graphs · Decision Intelligence · Module Reference · Recipes · CLI · Integrations · Performance · Install

Watch the full platform walkthrough →
Knowledge Explorer · Context Graphs · Reasoning Engine · Decision Intelligence · Ontology Hub
pip install semanticafrom semantica.context import ContextGraph
graph = ContextGraph(advanced_analytics=True)
# Every agent decision becomes a queryable, auditable knowledge node
decision_id = graph.record_decision(
category="vendor_selection",
scenario="Choose cloud provider for HIPAA workload",
reasoning="AWS offers BAA, mature HIPAA tooling, and existing team expertise",
outcome="selected_aws",
confidence=0.93,
)
# Ask "why did this happen?" and get a real, structured answer
chain = graph.trace_decision_chain(decision_id) # full causal ancestry
similar = graph.find_similar_decisions("cloud vendor", max_results=5) # precedents
impact = graph.analyze_decision_impact(decision_id) # downstream influence map
compliant = graph.check_decision_rules({"category": "vendor_selection"}) # policy gateVerify your install in 5 seconds:
semantica doctor
# Python 3.11.9 pass
# semantica 0.5.0 pass
# faiss vector store pass
# Config file pass ~/.semantica/config.yamlTip
Run semantica doctor immediately after install to verify all backends are wired correctly. It catches misconfigured API keys, missing drivers, and backend connectivity issues before they surface at runtime.
If Semantica solves a real problem for you, a star helps others find it.
The full data pipeline and decision intelligence lifecycle are documented with Mermaid flowcharts in ARCHITECTURE.md:
- Full data pipeline: all sources → ingest → parse → normalize → split → extract → deduplication → KG → storage → export
- Decision intelligence lifecycle: record → link → query → govern → audit
Every component is independently importable. Use one module or all of them.
| Vector DB + RAG | Plain LLM Memory | Semantica | |
|---|---|---|---|
| Recall method | Embedding similarity | Token window | Graph traversal + semantic search |
| Decision history | Not stored | Not stored | First-class queryable objects |
| Provenance | None | None | W3C PROV-O, source-linked |
| Reasoning | None | Black box | Forward chain, Rete, Datalog, SPARQL |
| Conflict detection | Silent overwrite | Silent overwrite | Detected, flagged, resolved |
| Time travel | No | No | Point-in-time graph snapshots |
| Compliance export | None | None | PROV-O, SHACL, OWL, RDF |
| Policy enforcement | None | None | Built-in rule engine + SHACL |
| Entity resolution | No | No | Blocking + semantic deduplication |
| Multi-agent context | Separate per agent | Separate per agent | Single shared intelligence layer |
Important
Semantica complements your existing stack — it does not replace anything you already have. Keep your LLM, vector store, and agent framework exactly as they are. Semantica sits alongside them as the accountability and intelligence layer, adding structured decision records, causal reasoning, W3C PROV-O provenance, ontology governance, conflict detection, and compliance-grade audit trails. Your stack handles retrieval and generation. Semantica handles accountability and explainability. They are built to work together.
Note
Semantica is designed for AI agents, GraphRAG systems, enterprise knowledge intelligence, and temporal reasoning applications. The reasoning engines, KG construction, and provenance layer are fully deterministic; no LLM is required to use them.
Most AI frameworks are built for retrieval. Semantica is built for accountability. The comparison below focuses on the intelligence capabilities that define the difference.
| LangChain | LlamaIndex | MS GraphRAG | Mem0 | Zep | Semantica | |
|---|---|---|---|---|---|---|
| Knowledge Graph construction | ⚡ Plugin | ⚡ PropertyGraph | ⚡ Community KG | ❌ | ❌ | ✅ Native, full-stack |
| Decision tracking | ❌ | ❌ | ❌ | ❌ | ❌ | ✅ First-class objects |
| Audit trail & provenance | ❌ | ❌ | ❌ | ❌ | ❌ | ✅ W3C PROV-O, exportable |
| Explainable reasoning | ❌ | ❌ | ❌ | ❌ | ❌ | ✅ Rete · Datalog · SPARQL |
| Ontology (OWL / SHACL) | ❌ | ❌ | ❌ | ❌ | ❌ | ✅ Generation + visual editor |
| Conflict detection | ❌ | ❌ | ❌ | ❌ | ❌ | ✅ 5 resolution strategies |
| Bi-temporal graph & time travel | ❌ | ❌ | ❌ | ❌ | ❌ | ✅ Point-in-time snapshots |
| Entity resolution | ❌ | ⚡ Partial | ⚡ Partial | ❌ | ⚡ Partial | ✅ Blocking + semantic dedup |
| Multi-agent shared context | ⚡ LangGraph | ⚡ Partial | ❌ | ✅ | ⚡ Partial | ✅ Single shared graph |
| Policy enforcement | ❌ | ❌ | ❌ | ❌ | ❌ | ✅ SHACL + rule engine |
✅ Full support ⚡ Partial / via plugin ❌ Not supported
The key distinction: LangChain, LlamaIndex, and MS GraphRAG are excellent retrieval and orchestration layers. Mem0 and Zep excel at personal agent memory. None of them answer "prove what your AI decided, why, and whether it complied with policy." Semantica is built specifically for that question.
A Context Graph is the structured memory layer that traditional RAG is missing. Instead of flat embeddings that answer "what is similar?", a Context Graph answers "what is connected, why, and how?"
Every entity, relationship, decision, and fact is a first-class node, queryable by graph traversal and neighbor expansion. Entities link to source documents. Decisions link to evidence and consequences. Facts carry full provenance. Conflicts are detected, not silently overwritten.
from semantica.context import ContextGraph, AgentContext
from semantica.vector_store import VectorStore
graph = ContextGraph(advanced_analytics=True)
# Add nodes with typed properties
graph.add_node("acme_corp", "Organization", name="Acme Corp", industry="SaaS")
graph.add_node("alice_chen", "Person", name="Alice Chen", role="CTO")
graph.add_node("contract_001", "Contract", value=2_400_000, currency="USD")
# Add typed, weighted edges (extra kwargs become edge metadata)
graph.add_edge("alice_chen", "acme_corp", edge_type="works_for", since="2019-03-01")
graph.add_edge("acme_corp", "contract_001", edge_type="party_to", signed="2024-01-15")
# BFS traversal - hop through the graph from any node
neighbors = graph.get_neighbors("acme_corp", hops=2)
# Point-in-time snapshot - the graph as it existed on any past date
snapshot = graph.state_at("2024-01-01")
# AgentContext - high-level API for agent memory workflows
vs = VectorStore(backend="faiss")
ctx = AgentContext(vector_store=vs, knowledge_graph=graph)
ctx.store("Alice approved the Acme renewal in Q1 2024", conversation_id="conv_001")
retrieved = ctx.retrieve("who approved the Acme contract?")Why graph over embeddings:
- Traversal finds connections embeddings miss, including a person 3 hops from a contract
- Every node carries provenance so you can always ask "where did this come from?"
- Conflicts are detected and flagged before they corrupt your knowledge base
- Point-in-time snapshots let you replay history without reprocessing
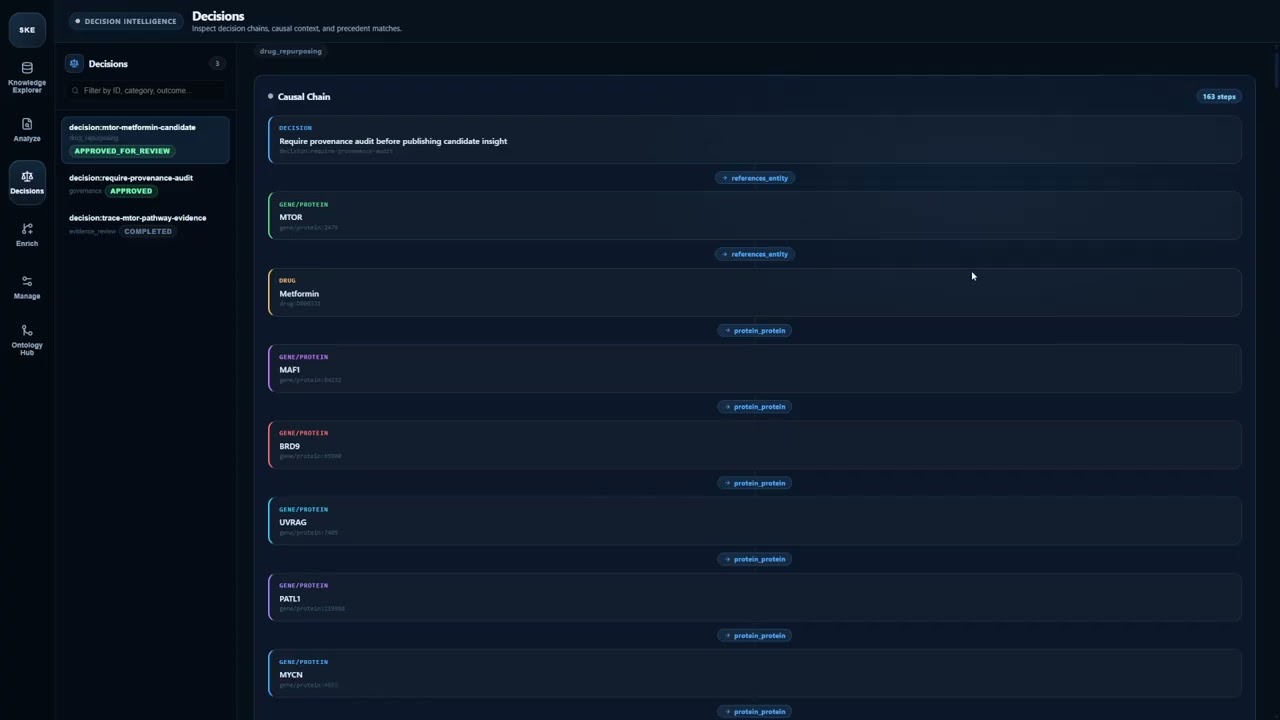
Decision Intelligence turns every AI choice from an ephemeral inference into a permanent, auditable, queryable record. It answers "what did your AI decide, why, and what happened next?" The question regulators and enterprise risk teams are asking with increasing urgency.
In Semantica, a decision is not a log line. It is a first-class graph node with a full lifecycle:
Important
In regulated domains (healthcare, finance, legal, government), every AI decision must be traceable to a source and defensible to an auditor. record_decision() creates a permanent, structured record exportable as W3C PROV-O, the format most compliance frameworks accept for regulator submission.
record_decision() → stored as a graph node with full structured context
add_causal_relationship() → linked to upstream causes and downstream effects
find_similar_decisions() → semantic precedent search across all past decisions
trace_decision_chain() → full causal ancestry back to root causes
analyze_decision_impact() → downstream influence map - everything this decision affected
check_decision_rules() → policy compliance gate against configurable rule sets
export / audit trail → W3C PROV-O, CSV, or JSON for regulator submission
from semantica.context import ContextGraph
graph = ContextGraph(advanced_analytics=True)
# Record decisions with full structured context
app_id = graph.record_decision(
category="credit_application",
scenario="Personal loan, $85k income, 31% DTI, 3yr employment",
reasoning="Income meets threshold; employment stable; no adverse credit events",
outcome="proceed_to_underwriting",
confidence=0.88,
metadata={"applicant_id": "A-7291"},
)
uw_id = graph.record_decision(
category="loan_underwriting",
scenario="Underwriting review for A-7291",
reasoning="DTI within policy; clean 36-month credit history",
outcome="approved",
confidence=0.94,
)
rate_id = graph.record_decision(
category="interest_rate",
scenario="Rate assignment for approved loan A-7291",
outcome="rate_set_8.9pct",
reasoning="Prime + 2.4% based on risk tier B2",
confidence=0.99,
)
# Build the auditable causal chain
graph.add_causal_relationship(app_id, uw_id, relationship_type="triggers")
graph.add_causal_relationship(uw_id, rate_id, relationship_type="enables")
# Query the intelligence
chain = graph.trace_decision_chain(rate_id)
similar = graph.find_similar_decisions("personal loan approval, 31% DTI", max_results=5)
impact = graph.analyze_decision_impact(uw_id)
compliant = graph.check_decision_rules({"category": "loan_underwriting", "confidence": 0.94})
insights = graph.get_decision_insights()Semantica is a full platform. Every module is independently importable and composable. Below are working examples for each.
Ingest from files, web, databases, APIs, streams, email, Git repos, Parquet, Snowflake, or MCP servers, all through a unified interface.
from semantica.ingest import FileIngestor, WebIngestor, ParquetIngestor, DBIngestor
# Ingest an entire directory of contracts (PDF, DOCX, HTML, TXT)
docs = FileIngestor().ingest_directory("./contracts/", recursive=True)
# Ingest live web content with robots.txt compliance
pages = WebIngestor().ingest_url("https://example.com/reports/annual-2024.html")
# Ingest structured data from Parquet with Snappy compression
records = ParquetIngestor().ingest("./data/transactions.parquet")
# Ingest from a SQL database - specify which tables to pull
rows = DBIngestor().ingest_database(
connection_string="postgresql://user:pass@localhost/mydb",
include_tables=["customer_events"],
max_rows_per_table=50_000,
)Supported sources: Local files (PDF, DOCX, PPTX, HTML, TXT, CSV, JSON, YAML, Excel, XML) · Web pages · RSS/Atom feeds · REST APIs · Databases (PostgreSQL, MySQL, SQLite, Oracle, SQL Server) · Parquet datasets · Snowflake · Git repositories · Email (IMAP/POP3) · Message streams (Kafka, RabbitMQ, Kinesis, Pulsar) · MCP resources
Extract structured knowledge from raw text in one pass.
from semantica.semantic_extract import (
NamedEntityRecognizer,
RelationExtractor,
EventDetector,
TripletExtractor,
)
text = """
Anthropic CEO Dario Amodei announced a $7.3B Series E funding round in partnership
with Google and Spark Capital, valuing the company at $61.5B as of Q4 2024.
"""
# Named entity recognition with confidence thresholding
ner = NamedEntityRecognizer(confidence_threshold=0.7)
entities = ner.extract_entities(text)
# → [Entity(name="Dario Amodei", type="PERSON"), Entity(name="Anthropic", type="ORG"),
# Entity(name="Google", type="ORG"), Entity(name="$7.3B", type="MONEY"), ...]
# Relationship extraction - bidirectional support
rel_extractor = RelationExtractor(confidence_threshold=0.6, bidirectional=True)
relations = rel_extractor.extract_relations(text, entities=entities)
# → [Relation(subject="Dario Amodei", predicate="ceo_of", object="Anthropic"),
# Relation(subject="Anthropic", predicate="raised", object="$7.3B Series E"), ...]
# Event detection with temporal processing
events = EventDetector(extract_participants=True, extract_time=True).detect_events(text)
# → [Event(type="FUNDING", participants=["Anthropic","Google","Spark Capital"],
# amount="$7.3B", date="Q4 2024")]
# RDF triplets with optional provenance metadata
triplets = TripletExtractor(include_temporal=True, include_provenance=True).extract_triplets(text)
# → [("Anthropic", "valuation", "$61.5B"), ("Dario Amodei", "is_ceo_of", "Anthropic"), ...]Build a production knowledge graph from documents and run graph algorithms over it.
from semantica.ingest import FileIngestor
from semantica.kg import (
GraphBuilder,
GraphAnalyzer,
CentralityCalculator,
CommunityDetector,
PathFinder,
LinkPredictor,
BiTemporalFact,
)
from datetime import datetime
# Build KG - merge duplicate entities, track temporal edges
sources = FileIngestor().ingest_directory("./contracts/", recursive=True)
kg = GraphBuilder(merge_entities=True, enable_temporal=True).build(sources)
# Graph analytics
analyzer = GraphAnalyzer()
analysis = analyzer.analyze_graph(kg) # full graph metrics
centrality = CentralityCalculator()
degree = centrality.calculate_degree_centrality(kg) # most-connected entities
betweenness = centrality.calculate_betweenness_centrality(kg)
communities = CommunityDetector().detect_communities(kg, method="louvain") # natural clusters
path = PathFinder().find_shortest_path(kg, "alice_chen", "contract_001")
predictions = LinkPredictor().predict_links(kg, top_k=10) # relationship predictions
# Bi-temporal facts - track valid time vs. recorded time independently
fact = BiTemporalFact(
valid_from=datetime(2024, 3, 1),
valid_until=datetime(2025, 1, 1),
recorded_at=datetime(2024, 3, 5),
)Run explainable rule-based inference, not a black box.
from semantica.reasoning import ReteEngine, Rule, Fact, RuleType
rete = ReteEngine()
rete.build_network([
Rule(
rule_id="aml_flag",
name="Flag high-risk transactions",
conditions=[
{"field": "amount", "operator": ">", "value": 10_000},
{"field": "country", "operator": "in", "value": ["IR", "KP", "SY"]},
],
conclusion="flag_for_compliance_review",
rule_type=RuleType.IMPLICATION,
),
Rule(
rule_id="velocity_check",
name="Flag rapid sequential transfers",
conditions=[
{"field": "transfers_in_1h", "operator": ">", "value": 5},
{"field": "total_amount", "operator": ">", "value": 50_000},
],
conclusion="flag_velocity_breach",
rule_type=RuleType.IMPLICATION,
),
])
rete.add_fact(Fact("tx_001", "transaction", [{"amount": 15_000, "country": "IR"}]))
flagged = rete.match_patterns()
# → [{"rule": "aml_flag", "matched_facts": ["tx_001"], "conclusion": "flag_for_compliance_review"}]# Recursive Datalog - natural language for graph queries
from semantica.reasoning import DatalogReasoner
engine = DatalogReasoner()
engine.add_fact("parent(tom, bob)")
engine.add_fact("parent(bob, ann)")
engine.add_fact("parent(ann, pat)")
engine.add_rule("ancestor(X, Y) :- parent(X, Y).")
engine.add_rule("ancestor(X, Z) :- parent(X, Y), ancestor(Y, Z).")
ancestors = engine.query("ancestor(tom, ?X)")
# → [{"X": "bob"}, {"X": "ann"}, {"X": "pat"}]# Explainable reasoning - trace the path, not just the answer
from semantica.reasoning import ExplanationGenerator, Reasoner
reasoner = Reasoner()
result = reasoner.infer(kg, rules=[...])
explainer = ExplanationGenerator()
explanation = explainer.generate(result)
# → Explanation(conclusion="...", steps=[ReasoningStep(...)], justification=Justification(...))Drop-in vector store with 7 backends, hybrid search, and decision-aware retrieval.
from semantica.vector_store import VectorStore, HybridSearch
# Works with FAISS, Qdrant, Weaviate, Milvus, Pinecone, PgVector, or in-memory
vs = VectorStore(backend="qdrant", dimension=1536)
# Store a decision with scenario description and outcome
vs.store_decision(
scenario="Personal loan A-7291, $85k income, 31% DTI, 3yr employment",
outcome="approved",
confidence=0.94,
category="loan_underwriting",
)
# Semantic similarity search
results = vs.search(
query="personal loan approval with low DTI",
limit=10,
)
# Hybrid search - dense + sparse retrieval in one pass with RRF fusion
hs = HybridSearch(vector_store=vs)
hits = hs.search("high-risk transactions 2024")
# Explain why a decision was retrieved
explanation = vs.explain_decision(results[0]["id"])Caution
Mixing vectors generated from different embedding models in the same VectorStore index leads to inconsistent similarity scores. Always use a single embedding model per index, or isolate per-model data using namespaces.
KG-aware splitting that preserves entity boundaries, relation triplets, and ontology concepts, essential for GraphRAG pipelines.
from semantica.split import TextSplitter, EntityAwareChunker, RelationAwareChunker
text = open("contracts/master_agreement.txt").read()
# Standard recursive chunking
chunks = TextSplitter(method="recursive", chunk_size=1000, chunk_overlap=200).split(text)
# Entity-aware chunking - never splits a named entity across chunks (GraphRAG)
chunks = TextSplitter(method="entity_aware", ner_method="llm", chunk_size=1000).split(text)
# Relation-aware chunking - preserves (subject, predicate, object) triplets intact
chunks = RelationAwareChunker(chunk_size=1000, preserve_triplets=True).chunk(text)
# Graph-based chunking - uses centrality to find natural community boundaries
chunks = TextSplitter(method="graph_based", chunk_size=1000).split(text)
# Hierarchical chunking - multi-level (section → paragraph → sentence)
chunks = TextSplitter(method="hierarchical", levels=["section", "paragraph"]).split(text)Supported methods: recursive · token · sentence · paragraph · semantic_transformer · entity_aware · relation_aware · graph_based · ontology_aware · hierarchical · community_detection · centrality_based · llm
Every fact is linked to its source. No black boxes, no mystery outputs.
from semantica.provenance import ProvenanceManager
prov = ProvenanceManager(storage_path="./provenance.db")
# Track where every entity came from
prov.track_entity(
entity_id="acme_corp",
source="contracts/acme_master_agreement_2024.pdf",
metadata={"page": 1, "confidence": 0.97, "extractor": "NamedEntityRecognizer"},
)
prov.track_relationship(
relationship_id="alice_works_for_acme",
source_entity_id="alice_chen",
target_entity_id="acme_corp",
source="hr_records/employees_q1_2024.csv",
)
# Answer "where did this come from?"
lineage = prov.get_lineage("acme_corp")
trail = prov.trace_lineage("alice_chen") # full ancestor chain
entry = prov.get_provenance("acme_corp")Generate ontologies from data, validate shapes, and manage your vocabulary.
from semantica.ontology import OntologyGenerator, OntologyValidator
data = {
"entities": [
{"id": "acme_corp", "type": "Organization", "industry": "SaaS", "founded": 2012},
{"id": "alice_chen", "type": "Person", "role": "CTO", "since": 2019},
],
"relationships": [
{"source": "alice_chen", "target": "acme_corp", "type": "works_for"},
],
}
gen = OntologyGenerator(base_uri="https://semantica.dev/ontology/")
ontology = gen.generate_ontology(data)
classes = gen.infer_classes(data)
props = gen.infer_properties(data, classes)
optimized = gen.optimize_ontology(ontology)
# Validate against SHACL shapes
validator = OntologyValidator()
report = validator.validate(ontology)
# → ValidationResult(conforms=True, errors=[], warnings=[])Detect and resolve conflicting facts from multiple sources before they corrupt your knowledge base.
from semantica.conflicts import ConflictDetector, ConflictResolver, SourceTracker
entities_from_source_a = [
{"id": "alice_chen", "role": "CTO", "salary": 250_000, "start_date": "2019-03-01"},
]
entities_from_source_b = [
{"id": "alice_chen", "role": "VP Eng", "salary": 275_000, "start_date": "2019-03-01"},
]
# Detect all conflict types: value, type, relationship, temporal, logical
detector = ConflictDetector()
conflicts = detector.detect_conflicts(entities_from_source_a + entities_from_source_b)
# → [Conflict(entity="alice_chen", field="role", values=["CTO","VP Eng"], severity="HIGH"),
# Conflict(entity="alice_chen", field="salary", values=[250000,275000], severity="MEDIUM")]
# Resolve using multiple strategies
resolver = ConflictResolver()
resolved = resolver.resolve(conflicts, strategy="credibility_weighted") # weighted by source trust
resolved = resolver.resolve(conflicts, strategy="temporal") # prefer most recent
resolved = resolver.resolve(conflicts, strategy="voting") # majority wins
# Track source credibility over time
tracker = SourceTracker()
tracker.track("source_a", credibility=0.85)
tracker.track("source_b", credibility=0.72)Block, cluster, and merge duplicates with semantic similarity. 6.98× faster than baseline.
from semantica.deduplication import DuplicateDetector, EntityMerger
entities = [
{"id": "e1", "name": "Acme Corporation", "domain": "acme.com"},
{"id": "e2", "name": "Acme Corp.", "domain": "acme.com"},
{"id": "e3", "name": "ACME Corp", "domain": "acme.co"},
{"id": "e4", "name": "Globex Industries", "domain": "globex.com"},
]
detector = DuplicateDetector(similarity_threshold=0.75, use_clustering=True)
candidates = detector.detect_duplicates(entities)
groups = detector.detect_duplicate_groups(entities)
# → DuplicateGroup(entities=["e1","e2","e3"], confidence=0.91, strategy="semantic+blocking")
merger = EntityMerger(preserve_provenance=True)
ops = merger.merge_duplicates(entities, strategy="keep_most_complete")
history = merger.get_merge_history()Standardize text, entities, dates, numbers, and encodings before building your knowledge graph.
from semantica.normalize import (
TextNormalizer,
EntityNormalizer,
DateNormalizer,
NumberNormalizer,
DataCleaner,
)
# Unicode, whitespace, casing, HTML tags, smart quotes
text = TextNormalizer().normalize(" Acme Corp.’s Q4 report… ")
# → "Acme Corp.'s Q4 report..."
# Alias resolution + entity disambiguation with confidence scores
names = EntityNormalizer().normalize_entity("ACME Corp.")
# → NormalizedEntity(canonical="Acme Corporation", type="Organization", confidence=0.91)
# Natural language date parsing with timezone conversion
dt = DateNormalizer().normalize_date("3 weeks ago")
# → datetime(2026, 5, 22, tzinfo=UTC)
# Unit conversion and currency normalization
price = NumberNormalizer().normalize("$1.25M USD")
# → NormalizedNumber(value=1_250_000, currency="USD")
# Deduplicate and impute missing values across a dataset
clean = DataCleaner().clean(records, dedup_threshold=0.9, fill_missing="mean")Compose ingestion, extraction, and graph-building into a declarative, parallel pipeline.
from semantica.pipeline import PipelineBuilder, ExecutionEngine
pipeline = (
PipelineBuilder()
.add_step("ingest", step_type="ingest", source="./contracts/", recursive=True)
.add_step("extract", step_type="ner_extract")
.add_step("relations", step_type="relation_extract")
.add_step("build_kg", step_type="kg_build", merge_entities=True)
.add_step("deduplicate", step_type="deduplicate", threshold=0.75)
.add_step("export", step_type="export", format="turtle", output="kg.ttl")
.connect_steps("ingest", "extract")
.connect_steps("extract", "relations")
.connect_steps("relations", "build_kg")
.connect_steps("build_kg", "deduplicate")
.connect_steps("deduplicate", "export")
.set_parallelism(4)
.build(name="contracts_pipeline")
)
engine = ExecutionEngine()
result = engine.execute(pipeline)
status = engine.get_status(pipeline)
progress = engine.get_progress(pipeline)Warning
Large-scale ingestion may require significant memory. For datasets exceeding 500k nodes, use StreamIngestor or enable incremental batch mode with GraphBuilder(incremental=True). Use set_parallelism() conservatively on memory-constrained machines.
Track when facts were true in the world vs. when they were recorded, and query either axis.
from semantica.context import ContextGraph
from semantica.kg import (
BiTemporalFact,
TemporalGraphQuery,
TemporalVersionManager,
TemporalNormalizer,
)
from datetime import datetime
graph = ContextGraph(advanced_analytics=True)
graph.add_node("alice_chen", "Person", role="VP Engineering")
graph.add_node("acme_corp", "Organization", valuation=1_200_000_000)
# Point-in-time snapshots - replay history without reprocessing
snapshot_2023 = graph.state_at("2023-06-01")
snapshot_2024 = graph.state_at("2024-01-01")
# Bi-temporal facts - valid_time is when true in the world;
# recorded_at is when you learned about it
fact = BiTemporalFact(
valid_from=datetime(2024, 3, 1),
valid_until=datetime(2025, 1, 1),
recorded_at=datetime(2024, 3, 5),
)
# Allen interval algebra - 13 temporal relations (before, during, overlaps, etc.)
tq = TemporalGraphQuery(graph)
facts_in_window = tq.query_time_range("2024-01-01", "2024-12-31")
# Normalize natural language temporal expressions
norm = TemporalNormalizer()
dt = norm.normalize("last quarter") # → datetime range for Q1 2026Export to any format required by regulators, graph databases, or downstream systems.
from semantica.export import (
RDFExporter,
JSONExporter,
ParquetExporter,
LPGExporter,
ReportGenerator,
)
kg = {"entities": [...], "relationships": [...]}
rdf = RDFExporter()
turtle_str = rdf.export_to_rdf(kg, format="turtle") # returns string
jsonld_str = rdf.export_to_rdf(kg, format="json-ld")
rdf.export(kg, "kg_audit.ttl", format="turtle")
rdf.export(kg, "kg_audit.jsonld", format="json-ld")
rdf.export(kg, "kg_audit.nt", format="n-triples")
# Columnar analytics - Snappy-compressed Parquet
ParquetExporter().export(kg, "kg_snapshot.parquet", compression="snappy")
# JSON knowledge graph
JSONExporter().export_knowledge_graph(kg, "kg.json")
# Neo4j / Memgraph Cypher statements for graph database import
LPGExporter().export(kg, "kg_import.cypher", method="cypher")
# Human-readable HTML / Markdown report
ReportGenerator().generate(kg, "audit_report.html", format="html")Render force-directed graphs, community maps, ontology hierarchies, and temporal dashboards.
from semantica.visualization import (
KGVisualizer,
OntologyVisualizer,
EmbeddingVisualizer,
TemporalVisualizer,
)
import numpy as np
kg = {"entities": [...], "relationships": [...]}
# Interactive force-directed graph (opens in browser)
viz = KGVisualizer(layout="force", color_scheme="default")
viz.visualize_network(kg, output="interactive", file_path="kg.html")
viz.visualize_communities(kg, communities, output="interactive")
viz.visualize_centrality(kg, centrality, centrality_type="degree")
viz.visualize_entity_types(kg, output="html", file_path="entity_types.html")
# Ontology class hierarchy
OntologyVisualizer().visualize_hierarchy(ontology, output="interactive")
# 2D embedding projection (UMAP / t-SNE / PCA)
EmbeddingVisualizer().visualize_2d_projection(
embeddings=np.array([...]),
labels=["entity_a", "entity_b"],
method="umap",
)
# Timeline scrubber - watch the graph evolve
TemporalVisualizer().visualize_timeline(kg, output="interactive")One shared intelligence layer. All agents read and write to the same context graph.
# pip install semantica[agno]
from agno.agent import Agent
from agno.team import Team
from agno.models.anthropic import Claude
from semantica.context import ContextGraph
from semantica.vector_store import VectorStore
from integrations.agno import AgnoSharedContext, AgnoDecisionKit, AgnoKGToolkit
shared = AgnoSharedContext(
vector_store=VectorStore(backend="faiss"),
knowledge_graph=ContextGraph(advanced_analytics=True),
decision_tracking=True,
)
researcher = Agent(
name="Researcher",
model=Claude(id="claude-sonnet-4-6"),
memory=shared.bind_agent("researcher"),
tools=[AgnoKGToolkit(context=shared)],
)
analyst = Agent(
name="Analyst",
model=Claude(id="claude-sonnet-4-6"),
memory=shared.bind_agent("analyst"),
tools=[AgnoDecisionKit(context=shared)],
)
team = Team(agents=[researcher, analyst], mode="coordinate")
# Researcher's findings are instantly available to the Analyst - no copy, no sync→ 40+ runnable notebooks in the cookbook
Tip
New to Semantica? Start with the cookbook notebooks. They walk through each module end-to-end with real datasets before you write production code. Each notebook is self-contained and runnable in under 5 minutes.
Copy-paste patterns for the most common use cases.
from semantica.ingest import FileIngestor
from semantica.split import TextSplitter
from semantica.semantic_extract import NamedEntityRecognizer, RelationExtractor
from semantica.kg import GraphBuilder
from semantica.vector_store import VectorStore, HybridSearch
from semantica.context import AgentContext
# 1. Ingest
docs = FileIngestor().ingest_directory("./docs/", recursive=True)
# 2. Entity-aware chunking - never splits an entity across a chunk boundary
splitter = TextSplitter(method="entity_aware", chunk_size=1000)
chunks = [splitter.split(doc["text"]) for doc in docs]
# 3. Extract entities and relations
ner = NamedEntityRecognizer(confidence_threshold=0.7)
rel_ext = RelationExtractor(confidence_threshold=0.6)
entities = [ner.extract_entities(chunk) for chunk_group in chunks for chunk in chunk_group]
# 4. Build KG
kg = GraphBuilder(merge_entities=True, enable_temporal=True).build(docs)
# 5. Hybrid retrieval
vs = VectorStore(backend="faiss")
ctx = AgentContext(vector_store=vs, knowledge_graph=kg)
ctx.store("Alice approved the Acme renewal in Q1 2024", conversation_id="c1")
results = HybridSearch(vector_store=vs).search("who approved the renewal?")from semantica.context import ContextGraph
from semantica.provenance import ProvenanceManager
from semantica.export import RDFExporter
graph = ContextGraph(advanced_analytics=True)
prov = ProvenanceManager(storage_path="./audit.db")
# Record the decision chain
d1 = graph.record_decision(
category="loan_application", scenario="A-7291, $85k income",
reasoning="Income threshold met", outcome="proceed", confidence=0.88,
)
d2 = graph.record_decision(
category="loan_underwriting", scenario="Underwriting A-7291",
reasoning="Clean credit history", outcome="approved", confidence=0.94,
)
graph.add_causal_relationship(d1, d2, relationship_type="triggers")
# Track provenance for every entity
prov.track_entity("applicant_A7291", source="loan_application_form.pdf",
metadata={"page": 1, "extractor": "NamedEntityRecognizer"})
# Export W3C PROV-O for regulator submission
kg = graph.export_graph()
RDFExporter().export(kg, "audit_trail.ttl", format="turtle")from semantica.reasoning import ReteEngine, Rule, Fact, RuleType
rete = ReteEngine()
rete.build_network([
Rule(
rule_id="sanctions_check",
name="Flag sanctioned-country transactions",
conditions=[
{"field": "amount", "operator": ">", "value": 10_000},
{"field": "country", "operator": "in", "value": ["IR", "KP", "SY", "CU"]},
],
conclusion="flag_for_compliance_review",
rule_type=RuleType.IMPLICATION,
),
])
rete.add_fact(Fact("tx_99", "transaction", [{"amount": 25_000, "country": "IR"}]))
matches = rete.match_patterns()
# → [{"rule": "sanctions_check", "matched_facts": ["tx_99"],
# "conclusion": "flag_for_compliance_review"}]from semantica.ingest import FileIngestor
from semantica.semantic_extract import NamedEntityRecognizer, RelationExtractor
from semantica.kg import GraphBuilder
from semantica.ontology import OntologyGenerator, OntologyValidator
from semantica.export import RDFExporter
sources = FileIngestor().ingest_directory("./contracts/")
ner = NamedEntityRecognizer(confidence_threshold=0.7)
entities = ner.extract_entities_batch([s["text"] for s in sources])
kg = GraphBuilder(merge_entities=True).build(sources)
gen = OntologyGenerator(base_uri="https://myco.dev/ontology/")
ont = gen.generate_ontology({"entities": entities[0], "relationships": []})
report = OntologyValidator().validate(ont)
if report.conforms:
RDFExporter().export({"entities": entities[0]}, "ontology.ttl", format="turtle")Benchmarks from v0.5.0 on a 118,000-node production graph:
| Operation | Before | After | Improvement |
|---|---|---|---|
| Node search (118k nodes) | 24 ms | 0.004 ms | 6,000× faster |
| Embedding cache hit | cold load | revision-based cache | 10× throughput |
| Semantic deduplication | baseline | optimized candidate gen | 6.98× faster |
| Candidate generation | baseline | blocking strategy | 63.6% faster |
Note
Benchmarks are from v0.5.0 on a 118,000-node production graph (AMD EPYC, 64 GB RAM). Results vary by hardware, dataset topology, and backend selection. Run semantica benchmark to measure performance on your own data.
Every capability is available from the terminal. The CLI ships with the package, no separate install required.
pip install semantica
semantica # startup dashboard
semantica --help # full grouped command reference
Start with semantica, verify with doctor, build a graph, and explore the command groups from one terminal.
$ semantica
███████╗███████╗███╗ ███╗ █████╗ ███╗ ██╗████████╗██╗ ██████╗ █████╗
██╔════╝██╔════╝████╗ ████║██╔══██╗████╗ ██║╚══██╔══╝██║██╔════╝ ██╔══██╗
███████╗█████╗ ██╔████╔██║███████║██╔██╗ ██║ ██║ ██║██║ ███████║
╚════██║██╔══╝ ██║╚██╔╝██║██╔══██║██║╚██╗██║ ██║ ██║██║ ██╔══██║
███████║███████╗██║ ╚═╝ ██║██║ ██║██║ ╚████║ ██║ ██║╚██████╗ ██║ ██║
╚══════╝╚══════╝╚═╝ ╚═╝╚═╝ ╚═╝╚═╝ ╚═══╝ ╚═╝ ╚═╝ ╚═════╝ ╚═╝ ╚═╝
╭─────────────────────────────────────────────────────────────────────────────╮
│ │
│ Knowledge Intelligence Platform • v0.5.0 │
│ │
│ 🕸️ Context Graphs ⚡ Decision Intelligence 🔍 Provenance │
│ 🧩 Knowledge Fusion 🧠 Reasoning Engine 📊 Explainability │
│ │
╰─────────────────────────────────────────────────────────────────────────────╯
Graph Store neo4j
Vector Store faiss
Profile default
Config ~/.semantica/config.yaml
Run semantica --help for all commands • semantica shell for interactive mode
$ semantica kg build -s ./contracts/ -s ./reports/ --store neo4j
contracts/ ████████████████████ 12/12 4.2s
reports/ ████████████████████ 8/8 2.9s
Knowledge graph built 1,847 nodes 4,203 edges 7.1s
$ semantica doctor
Python 3.11.9 pass
semantica 0.5.0 pass
neo4j backend pass neo4j://localhost:7687
faiss vector store pass
LLM provider warn OPENAI_API_KEY not set
Config file pass ~/.semantica/config.yaml
Command groups: ingest · parse · extract · kg · reason · decision · temporal · provenance · ontology · embed · deduplicate · validate · export · visualize · pipeline · server · explorer · mcp · doctor · shell · init · watch
Native plugin bundles for 8 editors · MCP server with 12 tools · 109-endpoint REST API · Agno first-class · All LLM providers already supported: OpenAI · Anthropic · Gemini · Mistral · Llama · Groq · Cohere · Azure · Bedrock · Ollama · DeepSeek · HuggingFace and more via LiteLLM
| Native Plugin Bundle | MCP Server + Plugin | ||||||
|---|---|---|---|---|---|---|---|
|
Claude Code 17 skills · 3 agents · hooks |
Cursor 17 skills · 3 agents |
Codex CLI 17 skills · 3 agents |
Windsurf plugin |
Cline plugin |
Continue plugin |
VS Code plugin |
OpenClaw MCP + plugin |
| MCP Server | REST API | ||||||
|
Claude Desktop MCP server |
GitHub Copilot REST API |
Roo Code REST API |
Goose REST API |
Kilo Code REST API |
Aider REST API |
Amazon Q REST API |
Zed REST API |
| Native Integration | |||||||
|---|---|---|---|---|---|---|---|
|
Agno First-class · pip install semantica[agno]
|
|||||||
| Already Supported via REST API & MCP | |||||||
|
LangChain REST API · MCP |
LangGraph REST API · MCP |
CrewAI REST API · MCP |
LlamaIndex REST API · MCP |
AutoGen REST API · MCP |
OpenAI Agents REST API · MCP |
Google ADK REST API · MCP |
|
| Native SDK Integration — Coming Soon | |||||||
|
LangChain Dedicated toolkit |
CrewAI Dedicated toolkit |
LlamaIndex Dedicated toolkit |
AutoGen Dedicated toolkit |
OpenAI Agents Dedicated toolkit |
Google ADK Dedicated toolkit |
||
Connect any MCP-compatible client (Claude Desktop, Windsurf, Cline, VS Code) in 30 seconds:
python -m semantica.mcp_server
# or via the installed entry point
semantica-mcp{
"mcpServers": {
"semantica": { "command": "python", "args": ["-m", "semantica.mcp_server"] }
}
}Tip
The fastest way to connect Claude Desktop, Windsurf, or Cline is python -m semantica.mcp_server. No extra configuration needed for local use; the server auto-discovers ~/.semantica/config.yaml.
12 tools exposed over MCP:
| Tool | What it does |
|---|---|
extract_entities |
NER on any text |
extract_relations |
Relation extraction |
record_decision |
Persist a decision node |
query_decisions |
Search decision history |
find_precedents |
Semantic precedent lookup |
get_causal_chain |
Full causal ancestry |
add_entity |
Add a KG node |
add_relationship |
Add a KG edge |
run_reasoning |
Execute rule set |
get_graph_analytics |
Centrality, communities |
export_graph |
Export to RDF/JSON/Parquet |
get_graph_summary |
Graph statistics |
# Start the backend
python -m semantica.server # port 8000
# Extract entities via REST
curl -X POST http://localhost:8000/api/extract/entities \
-H "Content-Type: application/json" \
-d '{"text": "Apple CEO Tim Cook announced record earnings."}'
# Record a decision
curl -X POST http://localhost:8000/api/decisions \
-H "Content-Type: application/json" \
-d '{
"category": "vendor_selection",
"scenario": "Choose ML cloud provider",
"reasoning": "Best GPU availability and pricing",
"outcome": "selected_aws",
"confidence": 0.91
}'
# Query the knowledge graph
curl http://localhost:8000/api/graph/neighbors/acme_corp?hops=2109 endpoints across: extract · kg · decisions · reasoning · provenance · ontology · embeddings · search · export · pipeline · temporal · deduplication
17 domain skills: extract · ingest · query · ontology · validate · deduplicate · embed · reason · decision · causal · temporal · provenance · policy · explain · export · change · visualize
3 specialized agents: kg-assistant · decision-advisor · explainability
Bundles for Claude Code, Cursor, Codex, Windsurf, Cline, Continue, VS Code, and OpenClaw in plugins/.
A browser-based graph workbench. Pan and zoom live graphs, scrub the timeline, review every decision's causal chain, resolve duplicates, and author your ontology visually. Built on React 19 + Sigma.js.
| Workspace | What you can do |
|---|---|
| Knowledge Graph | Live Sigma.js canvas with ForceAtlas2 layout, Ego Mode, semantic distance heatmap |
| Timeline | Scrub through temporal events and watch the graph evolve |
| Decisions | Browse the causal chain behind every recorded decision |
| Registry | Live audit log of every graph mutation |
| Entity Resolution | Review and merge duplicates |
| Ontology Hub | SHACL Studio, visual editor, cross-ontology alignments, SKOS browser |
| Lineage | W3C PROV-O provenance visualization for any entity |
Quickest way to start (no Node.js required):
pip install "semantica[explorer]"
semantica-explorer --graph my_graph.json
# Dashboard opens at http://127.0.0.1:8000For contributor / dev-server setup, see the full local setup guide:
→ explorer/README.md — Local Setup Guide
| Module | What it provides |
|---|---|
semantica.context |
Context graphs, agent memory, decision tracking, causal analysis, precedent search, policy engine |
semantica.kg |
KG construction, graph algorithms, centrality, community detection, temporal queries, link prediction |
semantica.semantic_extract |
NER · relation extraction · event detection · coreference · triplet generation |
semantica.reasoning |
Forward chaining · Rete · deductive · abductive · SPARQL · Datalog with explainable output |
semantica.vector_store |
FAISS · Pinecone · Weaviate · Qdrant · Milvus · PgVector · hybrid + filtered search |
semantica.split |
GraphRAG chunking: entity-aware · relation-aware · graph-based · ontology-aware · hierarchical |
semantica.provenance |
W3C PROV-O lineage · source tracking · revision history · audit log export |
semantica.ontology |
OWL generation · SHACL shape generation & validation · SKOS vocabulary management |
semantica.kg (temporal) |
Bi-temporal facts · Allen interval algebra · point-in-time snapshots · TemporalNormalizer · TemporalGraphQuery |
semantica.deduplication |
Blocking · hybrid · semantic strategies · entity merging with provenance |
semantica.conflicts |
Value/type/temporal conflict detection · credibility-weighted resolution · investigation guides |
semantica.normalize |
Text · entity · date · number · encoding normalization · data cleaning |
semantica.pipeline |
Pipeline DSL · parallel workers · validation · retry policies · progress tracking |
semantica.export |
RDF (Turtle/JSON-LD/N-Triples) · Parquet · OWL · SHACL · GraphML · Cypher · ArangoDB AQL |
semantica.ingest |
Files · web · public APIs · databases · Snowflake · MCP · email · Git repos · Parquet · streams |
semantica.graph_store |
Neo4j · FalkorDB · Apache AGE · Amazon Neptune |
semantica.visualization |
KG · ontology · embedding · temporal · community graph visualization |
explorer/ |
React 19 + Sigma.js browser workbench |
| Capability | Highlights |
|---|---|
| Context Graphs | Queryable graph of entities, decisions, relationships; causal links; cross-graph navigation |
| Decision Intelligence | record_decision · trace_decision_chain · find_similar_decisions · analyze_decision_impact · check_decision_rules |
| Temporal Intelligence | Point-in-time snapshots · Allen interval algebra (13 relations) · TemporalNormalizer · bi-temporal provenance |
| Distance Intelligence | N×N semantic distance matrices · ego-mode visualization · distance bands · 10× embedding cache |
| Semantic Extraction | NER · relation extraction · event detection · triplet generation · coreference · 6.98× faster dedup |
| Reasoning Engines | Forward chaining · Rete · deductive · abductive · SPARQL · Datalog with explainable output |
| GraphRAG Chunking | Entity-aware · relation-aware · graph-based · ontology-aware · community-detection chunking |
| Conflict Detection | Value / type / relationship / temporal / logical conflicts · 5 resolution strategies |
| Provenance | W3C PROV-O · every fact traced to source · audit log export JSON/CSV/RDF |
| Ontology Hub | SHACL Studio · visual editor · cross-ontology alignments · 5-dimension health dashboard |
| Vector Store | FAISS · Pinecone · Weaviate · Qdrant · Milvus · PgVector · hybrid + filtered search |
| Graph Databases | Neo4j · FalkorDB · Apache AGE · AWS Neptune |
| LLM Providers | All already supported today: OpenAI (GPT-4o, o1, o3) · Anthropic (Claude 4) · Google Gemini · Mistral · Meta Llama · Groq · Cohere · Azure OpenAI · AWS Bedrock · Ollama · DeepSeek · Perplexity · Together AI · Fireworks AI · Replicate · HuggingFace · via semantica.llms and LiteLLM |
- Distance Intelligence: 10× embedding cache, N×N semantic distance matrix, Ego Mode explorer, 5 new API endpoints
- Complete Ontology Hub: SHACL Studio, visual drag-and-drop editor, cross-ontology alignments, 5-dimension health dashboard, 16 new endpoints
- Modern CLI: Startup dashboard,
semantica doctor,semantica init,semantica watch,semantica shell, progress bars, structured error cards - Security: 12 vulnerabilities fixed (eval injection, pickle, SQL injection, XXE, SSRF, prompt injection, ReDoS, path traversal)
- 6,000× search speedup: O(log n) inverted index; 118k-node graphs: 24ms → 0.004ms
→ Full release notes · Changelog
Semantica is designed for environments where AI outputs must be explainable, auditable, and defensible.
- Healthcare: Clinical decision support, drug interaction graphs, and patient safety audit trails
- Finance: Fraud detection, AML compliance, regulatory risk knowledge graphs, and loan decision audit trails
- Legal: Evidence-backed research, contract analysis, case law reasoning, and privilege tracking
- Cybersecurity: Threat attribution, incident response timelines, and IOC provenance tracking
- Government: Policy decision records, classified information governance, and regulatory reporting
- Autonomous Systems: Decision logs, safety validation, and explainable AI for certification
pip install semantica # core
pip install semantica[all] # everythingpip install semantica[agno] # Agno multi-agent integration
pip install semantica[llm-litellm] # OpenAI, Anthropic, Gemini, Mistral, Llama, Groq, Cohere, Bedrock, Ollama, DeepSeek, and more
pip install semantica[graph-neo4j] # Neo4j graph store
pip install semantica[vectorstore-qdrant] # Qdrant vector store
pip install semantica[vectorstore-pinecone] # Pinecone vector store
pip install semantica[db-snowflake] # Snowflake
pip install semantica[ingest-parquet] # Parquet / PyArrow
pip install semantica[viz] # HTML interactive visualization
pip install semantica[watch] # Directory file watcherImportant
For production deployments, use Docker or Kubernetes rather than a local pip install. Set SEMANTICA_SECRET_KEY, configure a persistent graph store (Neo4j / FalkorDB), and point the vector store at a hosted backend (Qdrant / Pinecone). See ARCHITECTURE.md for the full deployment topology.
# From source
git clone https://github.com/semantica-agi/semantica.git
cd semantica && pip install -e ".[dev]" && pytest tests/On-premises deployment · Private cloud · Custom domain implementations · SLA-backed support · Professional services for regulated industries (healthcare, finance, legal, government).
getsemantica.ai for enterprise solutions and pricing.
| Discord | discord.gg/sV34vps5hH: real-time help, showcases, and announcements |
| GitHub Discussions | Q&A and feature requests |
| GitHub Issues | Bug reports |
| Documentation | docs.getsemantica.ai |
| Cookbook | 40+ runnable Jupyter notebooks |
| Changelog | CHANGELOG.md · Release Notes |
All contributions are welcome: bug fixes, features, tests, and documentation.
- Fork the repo and create a branch
pip install -e ".[dev]"- Write tests alongside your changes (
pytest tests/) - Open a PR and tag
@KaifAhmad1for review
See CONTRIBUTING.md for full guidelines.